


PROSES
Asumsikan bahwa organisasi secara teratur mengumpulkan ulasan dari pelanggan. Juga asumsikan bahwa semua ulasan dikumpulkan sebagai pertanyaan terbuka.
Pendekatan khas dengan data tidak terstruktur seperti ini adalah bagi anggota staf untuk membaca setiap ulasan dan menandai sentimen sebagai “positif,” “netral,” atau “negatif” dan kemudian melakukan analisis agregat. Menggunakan ulasan yang ditandai sebelumnya sebagai data, model NLP dapat menganalisis ulasan dan tag yang ditugaskan sedemikian rupa sehingga, pada akhirnya, dapat secara otomatis memprediksi sentimen tanpa instruksi eksplisit.
Bandingkan ini dengan pendekatan berbasis aturan, di mana algoritma hanya akan mencari kata-kata spesifik yang disediakan oleh pengguna (misalnya, “hebat,” “baik,” “miskin,” atau “buruk”). Pendekatan berbasis aturan dengan cepat menjadi tidak efektif karena variabilitas dalam data meningkat. Hampir tidak mungkin untuk memberikan aturan yang cukup untuk menutupi banyak variasi yang mungkin. Pendekatan semacam itu hanya cocok jika data yang mendasarinya distandarisasi secara memadai. Pendekatan ML seperti NLP, bagaimanapun, membentuk pemahaman tentang data dengan sendirinya dan bahkan mungkin dapat membuat koneksi bernuansa yang seharusnya hampir tidak mungkin untuk kode (misalnya, dengan menyamakan “meningkatkan,” “meningkatkan,” “meningkatkan,” dan “ditingkatkan”).
Proses umum pengembangan model ML, secara berurutan, adalah sebagai berikut:
- Mengumpulkan dan memproses data yang relevan.
- Konversi data ke bentuk yang dapat dipahami mesin. Proses ini disebut “vektorisasi.”
- Mengelompokkan data vektor ke dalam kelompok terpisah, sehingga data dengan karakteristik serupa dikelompokkan bersama. Pilih beberapa pengamatan dari setiap cluster untuk membuat sampel populasi yang representatif.
- Latih model ML pada sampel.
- Tune model sesuai kebutuhan, kemudian menyebarkan dan terus memperbaruinya untuk mencapai hasil terbaik sebagai keadaan berubah.
PENGUMPULAN DATA DAN PREPROCESSING
Yang ideal adalah mendapatkan data sebanyak mungkin, lebih disukai ulasan pelanggan setidaknya selama dua tahun. Bekerja dengan kumpulan data yang relatif besar membantu model tidak terlalu sesuai atau menyesuaikan terlalu khusus dengan data pelatihan. Model pembelajaran mesin (ML) melatih sampel populasi tertentu. Karena pengambilan sampel biasanya dilakukan dengan menggunakan pendekatan yang telah ditentukan, beberapa bias dapat menyebabkan data pelatihan memiliki outlier, atau karakteristik / titik data yang mungkin tidak mewakili populasi yang lebih luas. Jika model “cocok” terlalu baik pada data pelatihan, ada sedikit ruang untuk menggeneralisasi hasil ke data yang belum pernah dilihat sebelumnya.
Preprocessing adalah langkah penting. Pepatah umum di dunia ilmu data adalah “sampah masuk, sampah keluar.” Semua algoritma pembelajaran mesin (ML) melatih data, jadi masuk akal bahwa data yang bersih dan berguna adalah kebutuhan untuk model pembelajaran mesin (ML) yang berharga. Preprocessing mengacu pada membuat data “siap” cukup untuk membiarkan model pembelajaran mesin (ML) secara efektif belajar darinya. Proses ini kadang-kadang disebut pementasan data atau perselisihan data.
Deskripsi ulasan pelanggan jarang bersih, dan banyak informasi mengandung sedikit atau tidak ada nilai untuk pengambilan keputusan evaluatif. Langkah praproses dapat mencari dan mengganti ulasan yang hilang dengan frasa yang sesuai (misalnya, “tidak tersedia”). Yang lain mungkin berurusan dengan tanda baca, yang biasanya tidak informatif dan dapat dihapus. Namun langkah preprocessing lain bisa menghapus kata-kata berhenti atau kata-kata yang umum di semua ulasan dan umumnya konektor dalam bahasa apapun (kata-kata seperti “dan,” “a,” “an,” dan “the”). Langkah-langkah preprocessing mana yang dilakukan tergantung pada bagaimana data yang mendasarinya terstruktur.
Pertimbangkan ulasan pelanggan hipotetis ini dari maskapai penerbangan yang mengandung kesalahan dan fragmen tata bahasa, seperti yang sering terjadi: “Pengalaman hebat di pesawat. kru sangat sopan. Makanannya enak. akan terbang lagi.” Pertimbangkan bagaimana anggota staf akan menganalisis ulasan ini. Mereka mungkin tidak akan memperhatikan kata-kata berhenti, tanda baca, atau kata-kata lain seperti “pesawat” atau “kru.” Sebaliknya, mereka akan fokus mencari kata kunci yang, menurut pengetahuan mereka tentang bahasa Inggris, menunjukkan bagaimana perasaan pelanggan selama penerbangan. Kata-kata “hebat,” “sopan,” dan “lezat” siap menunjukkan kepuasan. Meskipun tidak mudah terlihat, penggunaan kata-kata “akan” (bukan negatory “tidak akan”) dan “lagi” juga menunjukkan umpan balik positif.
Setelah praproses, token berikut tetap: hebat, pengalaman, pesawat, kru, sopan, makanan, lezat, akan terbang lagi. Frasa ini memiliki nilai informasi paling banyak untuk model ML karena berisi token unik yang membedakan kategori “positif” dari dua lainnya. Itu bukan untuk mengatakan bahwa itu berisi semua kata yang berguna; Preprocessing tidak pernah dapat membuat data benar-benar bersih. Tapi itu bisa membawanya ke tahap di mana model NLP akan dapat membuat tautan antara kata-kata tertentu dan tag yang sesuai. Manusia melakukan preprocessing ini secara tidak sadar berdasarkan pengetahuan tentang bahasa alami yang diperoleh sepanjang hidup mereka. Komputer, di sisi lain, memerlukan data ini untuk dipentaskan (kecuali tentu saja, model disediakan yang secara otomatis memproses data).
Data yang telah diproses sebelumnya yang berisi nilai informasi adalah prasyarat untuk melatih model ML apa pun. Dalam pengalaman saya, lebih mudah untuk mementeta data dalam alat seperti Alteryx dibandingkan dengan bahasa pemrograman. Saya sering mement stage data saya menggunakan perangkat lunak berpemilik sebelum melatih model saya di Python.
VEKTORISASI
Setelah data telah diproses sebelumnya, itu perlu diubah menjadi format yang dapat dikerjakan oleh mesin. Komputer tidak dapat memahami data bahasa alami kecuali diberikan kepada mereka dalam semacam kode numerik. Vektorisasi mewakili transaksi secara numerik. Ada beberapa teknik yang tersedia untuk data vektorisasi. Dua pendekatan yang paling umum adalah:
CountVectorizer. Ini adalah jenis vectorizer yang paling mudah. Seperti namanya, CountVectorizer membuat vektor dengan menghitung berapa kali token yang diberikan muncul dalam teks. Ungkapan “dia kerang untuk kerang di dekat pantai” akan direpresentasikan sebagai “1 2 1 1 1 1” karena semua kata selain “kerang” terjadi sekali.
Vectorizer TF-IDF. TF-IDF adalah singkatan dari “istilah frekuensi frekuensi-terbalik frekuensi dokumen.” Pendekatan ini didasarkan pada premis bahwa jika token tertentu muncul beberapa kali dalam frasa tetapi tidak sering dalam frasa lain, kemungkinan itu deskriptif dari frasa itu. TF-IDF menghasilkan vektor melalui analisis statistik.
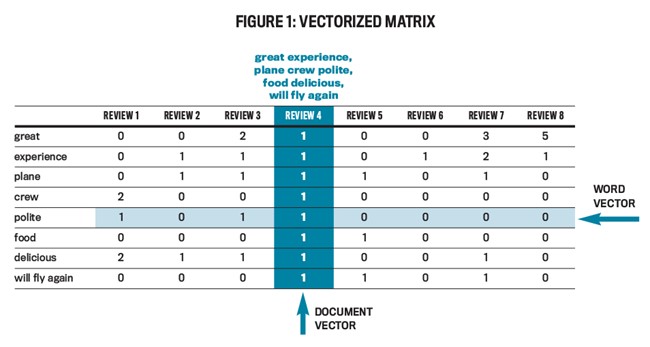
Tidak peduli pendekatannya, motif yang mendasarinya adalah untuk mewakili setiap ulasan pelanggan sebagai urutan angka terarah: vektor. Gambar 1 menggambarkan matriks vektor. Vektor yang disorot adalah untuk contoh ulasan yang disebutkan sebelumnya dan memiliki angka di samping setiap istilah yang tersedia yang menunjukkan berapa kali istilah itu terjadi dalam transaksi. Ketika model ML dilatih, tinjauan contoh dilewatkan sebagai vektor delapan dimensi yang sama dengan “1 1 1 1 1 1 1 1 1” (karena masing-masing token yang terdaftar terjadi sekali dalam frasa), sementara ulasan 6 dilewatkan sebagai “0 1 0 0 0 0 0 0 0” (menunjukkan bahwa hanya “pengalaman” yang terjadi dalam frasa; ini kemungkinan merupakan ulasan negatif).
CLUSTERING
Pembelajaran mesin (ML) memiliki tiga jenis utama: pembelajaran yang diawasi, pembelajaran tanpa pengawasan, dan pembelajaran penguatan. Pembelajaran yang diawasi berkaitan dengan data yang memiliki label, atau “jawaban.” Dalam hal ini, data berasal dari ulasan pelanggan sebelumnya, dan label adalah tag sentimen yang sesuai. Model pembelajaran mesin (ML) menggunakan pembelajaran yang diawasi untuk melatih, atau “belajar,” koneksi antara data dan label yang sesuai. Pembelajaran tanpa pengawasan digunakan untuk menemukan pola dalam data tanpa label eksternal. Ini bisa sangat berguna dalam mengelompokkan data ke dalam set serupa yang kemudian digunakan untuk membuat sampel pelatihan yang representatif. Pembelajaran penguatan adalah inovasi terbaru dalam ML dan berkaitan dengan pembuatan model melalui sistem hadiah.
Untuk membuat sampel representatif dari populasi vektor, saya lebih suka menggunakan teknik pembelajaran mesin (ML) tanpa pengawasan untuk mengelompokkan jenis titik data yang sama bersama-sama. Clustering adalah jenis pembelajaran tanpa pengawasan.
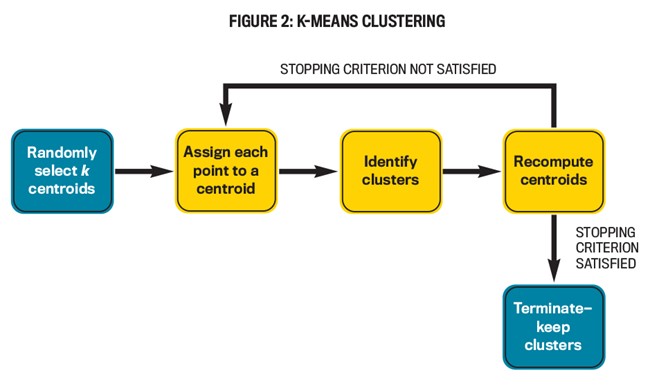
Algoritma pengelompokan k-means pertama kali dilengkapi dengan jumlah cluster (k) yang perlu dibuat. Kemudian memilih k ulasan sewenang-wenang (seperti yang diplot pada grafik) sebagai centroid cluster dan menetapkan setiap ulasan ke salah satu k centroids ini, biasanya ke yang terdekat. Algoritma kemudian mengkompilasi ulang centroids, menetapkan kembali ulasan ke sentroid baru (yang mungkin belum tentu menjadi ulasan dalam populasi), dan sebagainya. Ini berlanjut sampai kriteria berhenti (biasanya jumlah maksimum iterasi) tercapai.
Pengelompokan hierarkis sangat mirip dengan k-means, kecuali bahwa jumlah cluster tidak perlu disediakan sebelumnya. Juga, lebih banyak jenis kriteria berhenti dimungkinkan. Algoritma dimulai dengan setiap ulasan sebagai cluster sendiri dan berulang kali menggabungkan cluster bersama-sama berdasarkan perhitungan tertentu sampai kriteria berhenti tercapai.
Pengelompokan spasial berbasis kepadatan aplikasi dengan kebisingan (DBSCAN) adalah algoritma pengelompokan lanjutan yang mengelompokkan data berdasarkan seberapa padat area grafik yang diplot. Salah satu manfaat besar DBSCAN adalah potensi untuk menentukan outlier: Algoritma tidak perlu menetapkan setiap titik ke cluster, tidak seperti kebanyakan metode pengelompokan lainnya.
Saya biasanya mulai dengan dan tetap berpegang pada pengelompokan k-means karena kesederhanaannya dan persyaratan minimal untuk daya komputasi kecuali hasilnya menjamin perubahan. Jumlah cluster yang ideal akan tergantung pada variabilitas dalam ulasan pelanggan. Setelah mengelompokkan populasi, sejumlah ulasan tetap dapat dipilih dari setiap kluster dan sampel pelatihan dapat dibuat. Pendekatan ini memiliki dua manfaat:
- Ini memberikan setidaknya sebanyak ulasan dalam data pelatihan sebagai jumlah cluster, dan
- itu menciptakan sampel yang berisi ulasan dari semua kelompok, sehingga meningkatkan representasi populasinya. Data tinjauan pengelompokan bahkan dapat mengungkap pemisahan awal antara tiga sentimen pada grafik sehingga pengelompokan dapat dilihat. Proses k-means diilustrasikan pada Gambar 2.
PELATIHAN MODEL
Dengan asumsi satu ulasan dari setiap kluster disertakan dalam data pelatihan, sekarang berisi ulasan k. Ulasan ini seharusnya sudah memiliki label yang terkait dengannya; mereka telah ditandai di masa lalu oleh anggota staf. Ini menghadirkan pertanyaan penting: Jenis model ML mana yang terbaik untuk dilatih data? Itu adalah topik artikel itu sendiri, tetapi pada dasarnya ada banyak model untuk dipilih, dan dalam hal ini, banyak variasi yang mungkin. Ada informasi obyektif yang tersedia untuk memandu seleksi, tetapi banyak subjektivitas dimungkinkan. Pilihan termasuk teknik seperti tetangga k-terdekat, Naïve Bayes, regresi logistik, pohon keputusan, dan, untuk pemodelan yang lebih canggih, ansambel dan metode pembelajaran mendalam. Proses untuk melatih model ML serupa terlepas dari teknik yang dipilih.
Asumsikan bahwa model pembelajaran mesin (ML) dipilih. Selanjutnya membagi pelatihan yang ditetapkan menjadi dua set terpisah dalam proses yang dikenal sebagai pembagian tes kereta api, dengan satu set secara signifikan lebih besar dari yang lain. Pilihan populer termasuk split 80/20 atau 70/30.
Selanjutnya, latih model pembelajaran mesin (ML) pada kumpulan data yang lebih besar. Semua ini berarti bahwa perangkat lunak pilihan digunakan untuk meneruskan data melalui model ML. Model ini membandingkan setiap rekaman dalam kumpulan data dengan label yang sesuai (sentimen) dan mengembangkan “pengetahuan” tentang bagaimana ulasan spesifik terhubung ke label yang sesuai.
Skenario ideal (yang sulit dicapai) adalah mencapai keseimbangan yang benar antara kompleksitas dan generalisasi model pembelajaran mesin (ML). Model harus mencapai tingkat kompleksitas yang tepat, tidak hampir tidak menangkap hubungan dalam data pelatihan (tidak cukup kompleks) atau menangkapnya begitu dalam sehingga tidak dapat mentransfer pembelajaran ke data lain (tidak cukup umum). Dalam istilah pembelajaran mesin (ML), ini disebut sebagai trade-off bias-varians (untuk informasi lebih lanjut, lihat “Memahami Bias-Variance Tradeoff“ oleh Seema Singh).
Setelah model dilatih, akurasinya dapat diuji pada kumpulan data yang lebih kecil. Data ini tidak digunakan oleh model untuk memperbarui pengetahuan yang ada. Sebaliknya, model memprediksi sentimen berdasarkan pelatihan yang ada dan kemudian membandingkan prediksinya dengan label yang sebenarnya. Model ini sekarang dapat memberikan skor akurasi (didefinisikan sebagai jumlah total prediksi yang benar atas jumlah total transaksi dalam kumpulan data yang lebih kecil) tentang seberapa baik ia dapat mempelajari pola dalam kumpulan data yang lebih besar. Saya biasanya puas dengan akurasi awal sekitar 75%. Ini memberi saya kenyamanan bahwa data pelatihan saya cukup mewakili populasi dan bahwa akurasi ini kemungkinan akan meningkat karena saya terus meneruskan lebih banyak data melalui model.
PENYEBARAN DAN KAIZEN
Menyebarkan model pembelajaran mesin (ML) pada skala yang lebih besar dan menempatkannya melalui proses produksi adalah usaha terpisah yang lebih berkaitan dengan pengembangan perangkat lunak daripada ilmu data. Dalam praktiknya, ada seluruh tim yang dibentuk yang tugasnya difokuskan untuk menyebarkan model pembelajaran mesin (ML) di seluruh organisasi.
Namun, setelah model diterapkan, penting untuk mengingat konsep kaizen, yang berarti “perbaikan berkelanjutan” dan merupakan filosofi bisnis yang efektif dari Jepang. Pengembangan model pembelajaran mesin (ML) adalah proses berulang. Bahkan setelah penyebaran awal, umumnya ide yang baik untuk terus meneruskan data tambahan, menyetel parameter, dan bahkan memilih model yang berbeda berdasarkan perubahan keadaan akuntansi atau aspek bisnis lainnya dari organisasi.
AI dan pembelajaran mesin (ML) menghadirkan peluang menarik untuk mengubah profesi akuntansi menjadi lebih baik. NLP dapat digunakan untuk memahami kepuasan pelanggan dari ulasan, sebagai bagian dari perspektif pelanggan dari balanced scorecard. Meskipun ada banyak teknis yang terkait dengan proses, perangkat lunak ada saat ini yang memungkinkan orang dengan hanya pemahaman menengah tentang konsep untuk membangun model pembelajaran mesin (ML) yang sangat baik.
Bagi akuntan yang ingin mempelajari lebih lanjut tentang membangun model pembelajaran mesin (ML), langkah pertama adalah menjadi akrab dengan statistik menengah; Hampir semua model pembelajaran mesin (ML) memiliki algoritma statistik yang mendasarinya. Kedua, akuntan harus membaca lebih lanjut tentang pembelajaran mesin (ML) (mulai dengan “Machine Learning for Beginners”). Akhirnya, pengetahuan tentang alat untuk menerapkan pembelajaran mesin (ML) sangat penting. Python adalah bahasa yang paling populer untuk pekerjaan pembelajaran mesin (ML), mengingat fleksibilitas dan gudang data-sainsnya. Alteryx juga merupakan pilihan populer untuk analisis drag-and-drop. Berharap masa depan akuntansi akan terpengaruh secara radikal karena AI menjadi cara hidup.
Referensi:
- Arora, S. (2022, Maret 1). Natural Language Processing In Accounting.
- Fisher, I., Garnsey, M., & Hughes, M. (2016). Natural Language Processing in Accounting, Auditing and Finance: A Synthesis of the Literature with a Roadmap for Future Research. Intelligent Systems in Accounting Finance & Management.
- Google Image. (2022, Maret 6). www.google.com.
- Mayer , J., Stritzel, O., Eßwein , M., & Quick , R. (2020). Towards Natural Language Processing: An Accounting Case Study. Forty-First International Conference on Information Systems. India: Natural Language Processing.
- Tan, A. (2019, June 27). Four key applications of natural language processing for audit transformation.
